7 Minuten zum Lesen
In einem Zeitalter, in dem wir den digitalen Wandel leben und gestalten, stehen Versicherer an vorderster Front und bauen ihre Unternehmen zu digitalen Kraftwerken aus. Während sich die Mehrheit immer noch auf die Optimierung interner Prozesse konzentriert, gibt es eine Minderheit, die bezüglich Daten die nächste Stufe erreicht.
Das Datenpotenzial ist gewaltig, aber um Daten zu nutzen, brauchen Versicherer Datenwissenschaftler oder intelligente Tools, damit es funktioniert. Um Daten effektiv nutzen zu können, ist es wichtig, Geschäftsabläufe zu verstehen, relevante Datensätze zu erstellen und natürlich braucht man die richtigen Kompetenzen in den Bereichen Analyse und Entscheidungsmodellierung. Wenn man all dies kombiniert, hat man die richtigen Werkzeuge zur Verfügung, die man für seine Daten verwenden kann. Tauchen wir also in die Welt der Vorreiter ein, um die sechs wichtigsten datenwissenschaftlichen Anwendungsbeispiele im Versicherungswesen kennen zu lernen.
1. Automatisierte Erkennung von Versicherungsbetrug
Die Aufdeckung von Betrug ist nicht nur entscheidend, um finanzielle Verluste zu verhindern, sie ist auch ein wichtiger Dienst für die Allgemeinheit. Und trotzdem gibt es Versicherer, deren Ansatz zur Betrugsaufdeckung weiterhin ausschließlich auf dem Bauchgefühl des Schadensregulierers beruht, was normalerweise zu übermäßig hohen Kosten führt. Mit dem Aufkommen von Big Data und einem stärkeren Zugriff auf externe Daten zur Erweiterung der Untersuchungen ist es an der Zeit, vom Bauchgefühl des Schadensregulierers zu einem eher datenbasierten Ansatz überzugehen, ohne die zusätzlichen Vorteile zu vergessen - deutliche Zeiteinsparung und signifikante Verfahrensoptimierung.
Betrugserkennungsplattformen ermöglichen, betrügerische Aktivitäten, verdächtige Verbindungen und subtile Verhaltensmuster mittels verschiedener Techniken, wie Text-Mining und Bild-Screening, aufzudecken. Um eine automatisierte Betrugserkennung zu ermöglichen, müssen die Algorithmen mit einer kontinuierlichen Datenmenge gespeist werden. Diese Daten stammen aus internen Datensätzen früherer Fälle betrügerischer Aktivitäten oder aus externen Betrugsversuchen, wobei Stichprobenverfahren zu deren Analyse angewandt werden. Auch hier werden vorhersagende Modellierungstechniken für die Analyse und Filterung von Betrugsfällen angewandt. Die Identifizierung von Verbindungen zwischen verdächtigen Aktivitäten hilft, Betrugsmuster zu erkennen, die zuvor nicht aufgedeckt wurden. Im Endeffekt werden Versicherer, die von diesen Plattformen Gebrauch machen, das Ausmaß betrügerischer Ansprüche deutlich reduzieren und dadurch erhebliche Einsparungen erzielen..

2. Dynamische Preisgestaltung im Versicherungswesen
Das altehrwürdige Prinzip der Versicherungswirtschaft ist das Konzept der „Solidarität“. Doch in einer Welt voller Daten und erstklassiger Techniken können Risiken immer häufiger auf individueller Basis eingeschätzt werden. Preisoptimierung ist ein komplexer Prozess. Ihr Kernsystem sollte nicht nur in der Lage sein, mit Preisoptimierungstechniken (wie dynamischer Preisgestaltung) umzugehen, es sollten auch gesetzliche Kontrollmechanismen vorhanden sein, um die Einhaltung von sich ändernden gesetzlichen Vorgaben zu gewährleisten.
Die Preisoptimierung verwendet zahlreiche Kombinationen aus verschiedenen Algorithmen und Methoden. Dabei werden Erkenntnisse aus nicht versicherungsmathematischen Big Data (Daten, die nicht mit den traditionellen Kosten- und Risikoanalysen in Zusammenhang stehen) gewonnen, um die Prämien auf der Grundlage dessen zu bestimmen, wie viel ein Kunde bereit ist, für das zu zahlen, was Sie als Versicherer anzubieten haben. Die Preisoptimierung verwendet zahlreiche Kombinationen aus verschiedenen Algorithmen und Methoden. Dabei werden Erkenntnisse aus nicht versicherungsmathematischen Big Data (Daten, die sich nicht auf die traditionellen Faktoren wie Risikomerkmale oder prognostizierte Kosten von Ansprüchen und Ausgaben beziehen) gewonnen. So wird die Preisoptimierung sorgfältig auf die Preissensibilität der Kunden abgestimmt. Spezielle Algorithmen geben Versicherern die Möglichkeit, die angebotenen Prämien dynamisch anzupassen. Ein langfristiger Vorteil der Preisoptimierung ist die Stärkung der Kundenbindung. Damit einher geht die Gewinn- und Einkommenssteigerung.
3. Customer Lifetime Value
Datenwissenschaftler sind in der Lage, einen tieferen Einblick in den tatsächlichen Wert eines Kunden zu gewinnen und zwar nicht aufgrund einer einmaligen Transaktion, sondern basierend auf der gesamten „Lebensdauer“ des Kunden. Die Berechnung des CLV-Wertes eines Kunden gibt Versicherern Aufschluss darüber, wie viel Zeit und Geld sie in die Akquisition investieren müssen und sorgt für einen eindeutigen KPI, der ein effektiveres Kundenbindungsmanagement ermöglicht.
Der Customer Lifetime Value (CLV) stellt den Wert eines Kunden für ein Unternehmen dar, ausgedrückt durch die Differenz zwischen den erzielten Einnahmen und den gezahlten Ausgaben, hochgerechnet auf die gesamte zukünftige Geschäftsbeziehung mit einem Kunden. Wenn Sie sich mehr für Gleichungen interessieren - der CLV wird wie folgt bestimmt:
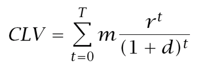
m = Marge | r = retention rate (Kundenbindungsrate | d = Diskontsatz | T = Zeit
Seien wir ehrlich - jeder Kunde liebt einen One-Stop-Shop. Wenn also jemand sein Auto bei Ihrem Unternehmen versichern möchte, ist es wahrscheinlich, dass er auch eine Hausrat- und Haftpflichtversicherung benötigt. Das bedeutet für Sie: Wenn eine Person ihr Auto versichert, besteht deren CLV-Wert also nicht nur aus den Einnahmen aus dieser Autoversicherung, sondern auch aus den Einnahmen anderer Produkte (gewichtet nach der Möglichkeit, dass die Person tatsächlich auch eine Hausrat- und Haftpflichtversicherung bei Ihnen abschließt). Natürlich verstehen wir, dass in manchen Fällen alle schönen Dinge zu einem Ende kommen. Menschen wechseln zu anderen Versicherern, so dass Sie in Ihrer Gleichung auch berücksichtigen sollten, dass einige Kunden möglicherweise nicht mehr da sein werden. Wenn Sie all dies kombinieren, verfügen Sie über eine recht solide Grundlage, von der aus Sie den CLV-Wert des Kunden ermitteln können.
Der CLV ist für alle Versicherer von größter Bedeutung, nicht nur für die Finanzanalysten, sondern auch für Schadensregulierer, Underwriter und Kundenbetreuer. Die steigenden Kundenanforderungen lassen sich recht gut bewältigen, wenn man sich den CLV anschaut. Wenn jemand einen Anspruch einreicht, ist es manchmal vorteilhaft, im Zweifelsfall mit Blick auf seinen CLV zu entscheiden.

4. Next-best Offer
Wie bei jedem Unternehmen ist Wachstum ein wichtiger Kernbereich für Versicherer. Es ist durchaus von Vorteil zu verstehen, was für ein Angebot Sie Ihren derzeitigen Kunden machen müssen, um sie zu halten, da es viel kostenintensiver ist, neue Kunden zu gewinnen.
Natürlich sind nicht alle Kunden gleich und nicht jeder Kunde hat die gleiche Kombination von Versicherungsprodukten. Dennoch sind Datenwissenschaftler in der Lage, allgemeine Trends bei Ihren Kunden zu entdecken. Zum Beispiel hat fast jeder Kunde im Alter von 30-35 Jahren eine Haftpflicht-, Auto- und Hausratversicherung. Ein etwa 30 Jahre alter Kunde, der nur eine Haftpflicht- und Autoversicherung hat, würde also wahrscheinlich auch die Hausratversicherung bei der gleichen Firma abschließen. Und da Sie aufgrund von Big Data bereits wissen, was ihre Hausratversicherung abdecken muss und zu welchem Preis, können Sie ziemlich genau ermitteln, welches Angebot Sie machen sollten. Das ist natürlich ein sehr einfaches Beispiel, aber Big Data ermöglicht Ihnen, versteckte Trends zu entdecken.
Die „Next Best Offer Algorithmen“ nutzen spezielle Filtersysteme, um die Präferenzen und Eigenarten der Kundenentscheidungen zu ermitteln. Die Algorithmen enthalten eine Analyse von Daten, die aus einfachen Fragebögen zu demographischen Daten und einigen persönlichen Angaben über die Versicherungserfahrung und das Versicherungsobjekt gewonnen wurden. Aufgrund dieser Erkenntnisse generieren die Suchmaschinen gezieltere Versicherungsangebote, die auf bestimmte Kunden zugeschnitten sind.
5. Automatisierte Risikobewertung
Ein automatisiertes Risikobewertungs-Tool hilft Ihnen, Ihren Kunden kennen zu lernen (KYC), eine ordnungsgemäße Kundenprüfung durchzuführen und die Risiken zu überprüfen, die ein Kunde versichern möchte. Die Einführung von Risikobewertungs-Tools in der Versicherungsbranche ermöglicht die Vorhersage von Risiken und begrenzt diese auf ein Minimum, um Verluste zu reduzieren.
Für Versicherer ist eine sorgfältige Risikobewertung ein zeitaufwändiger Prozess, da Sie sich nicht nur darauf konzentrieren, was sie versichern, sondern auch darauf, wen Sie versichern. Ein automatisiertes Risikobewertungs-Tool hilft Ihnen, in Echtzeit auf interne und externe Daten zuzugreifen. Basierend auf Ihrer Risikobereitschaft, gestützt durch entsprechende Daten, hilft Ihnen das Risikobewertungs-Tool, unmittelbare Entscheidungen zu treffen. Dies fördert nicht nur Ihre digitale Transformation, sondern steigert auch das Kundenerlebnis, da der Kunde in Sekundenschnelle feststellen kann, ob die Versicherungspolice genehmigt wurde oder nicht.
6. Automatisierte Schadensregulierung
Automatisierte Schadensregulierungslösungen zählen für Versicherer zu den besten Möglichkeiten, sich von der Konkurrenz abzuheben und ihre Kunden auf Lebenszeit zu binden. Von der ersten Schadensmeldung bis zur Regulierung können automatisierte Schadensregulierungslösungen Versicherern helfen, Arbeitsabläufe im Schadensfall zu optimieren, Zeit zu sparen und die Beziehung zum Versicherungsnehmer zu stärken.
Sach- und Unfallversicherer konzentrieren sich in hohem Maße auf die Bewertung von Schadensprognosen für einen bestimmten Schaden. Die Einschätzung stützt sich oft auf Informationen aus mehreren Quellen - E-Mails, verschiedene Papier- oder PDF-Formulare, wie z.B. Schadensprognosen oder Polizeiberichte. In solchen Fällen kann ein KI-Algorithmus darauf trainiert werden, aus jedem Dokument genau die richtigen Informationen zu gewinnen.
Sobald die Anspruchsdaten strukturiert sind, können robotergestützte Prozessautomatisierung (RPA) und künstliche Intelligenz (KI) zur Datenanalyse eingesetzt werden. Diese prüfen, ob der Versicherungsnehmer den passenden Versicherungsschutz hat. Wenn ein Antrag geprüft und als risikoarm eingestuft wurde, kann er zur sofortigen Auszahlung autorisiert oder, wenn er komplexer ist, einem Gutachter vorgelegt werden. Wenn ein Anspruch mit hohem Risiko identifiziert wurde, wird er zur weiteren Prüfung direkt an eine spezielle Untersuchungseinheit weitergeleitet.
Schlussfolgerungen
Daten sind im Versicherungssektor tief verwurzelt. Dennoch ist ihre effektive Nutzung für viele Versicherer eine große Herausforderung. Aber die Zukunft sieht rosig aus und eine genaue Überprüfung der sechs datenwissenschaftlichen Anwendungsbeispiele im Versicherungswesen macht Hoffnung auf das, was in der Versicherungswelt von morgen als gesunder Menschenverstand angesehen werden wird. Die Vorreiter in der Versicherungsbranche sind dabei, ihre Betrugserkennung und Schadensregulierung zu automatisieren, sich auf Wachstum zu konzentrieren (dynamische Preisgestaltung, CLV, Next Best Offer) und das Kundenerlebnis positiv zu verändern.